We Built a Phone Agent the Hard Way — You Can Do It in 30 Minutes
Introduction
This is the story of how we dedicated nights and weekends to building our own Phone Agent solution—something that could be achieved in just 30 minutes with existing platforms. It was a challenging but rewarding journey, and along the way, we gained invaluable insights that we’d like to share with you.
A few months ago, we started exploring challenges in Polish primary care. One problem stood out immediately: booking doctor appointments. Most appointments are still scheduled via phone calls. During flu season, dozens of people try to book an appointment as soon as the facility opens. Many spend hours trying to reach a receptionist, but their calls are never answered.
To solve this, we decided to create a Phone Agent to handle the calls. In this blog post, we’ll give you an overview of the Phone Agent landscape, and dive into how we built our own Agent. We’ll also discuss existing solutions and share our vision for the future of this domain.
Exploring Off-the-Shelf Solutions
We initially tested an off-the-shelf solution: bland.ai. It was impressive—we had a proof of concept up and running in less than 30 minutes. The Agent followed a script well, and we couldn’t perform any jailbreaks. However, we encountered three significant issues:
- The Agent was dumb. Likely due to the model size or prompt design. Improving this required evals, but they were really cumbersome to perform in a web interface. We couldn’t see this setup being production-ready, as AI Agents demand rigorous evaluations.
- Cost. To use a Polish phone number (via Twilio) we needed a $300 “PRO” plan (though this is now reportedly free).
- Polish language support. The transcription was poor and regularly misinterpreted speech.
These limitations led us to do the typical programmer thing—build our own Phone Agent infrastructure.
Building an AI Voice Agent
The Basics
Let’s now build an intuition on how our Agent should work. To create a Voice Agent, we needed three main components:
1. Speech-to-Text (STT): Convert user speech into text.
2. Language Model (LLM): Analyze user speech text and generate a response.
3. Text-to-Speech (TTS): Convert the Agent’s text response into speech.
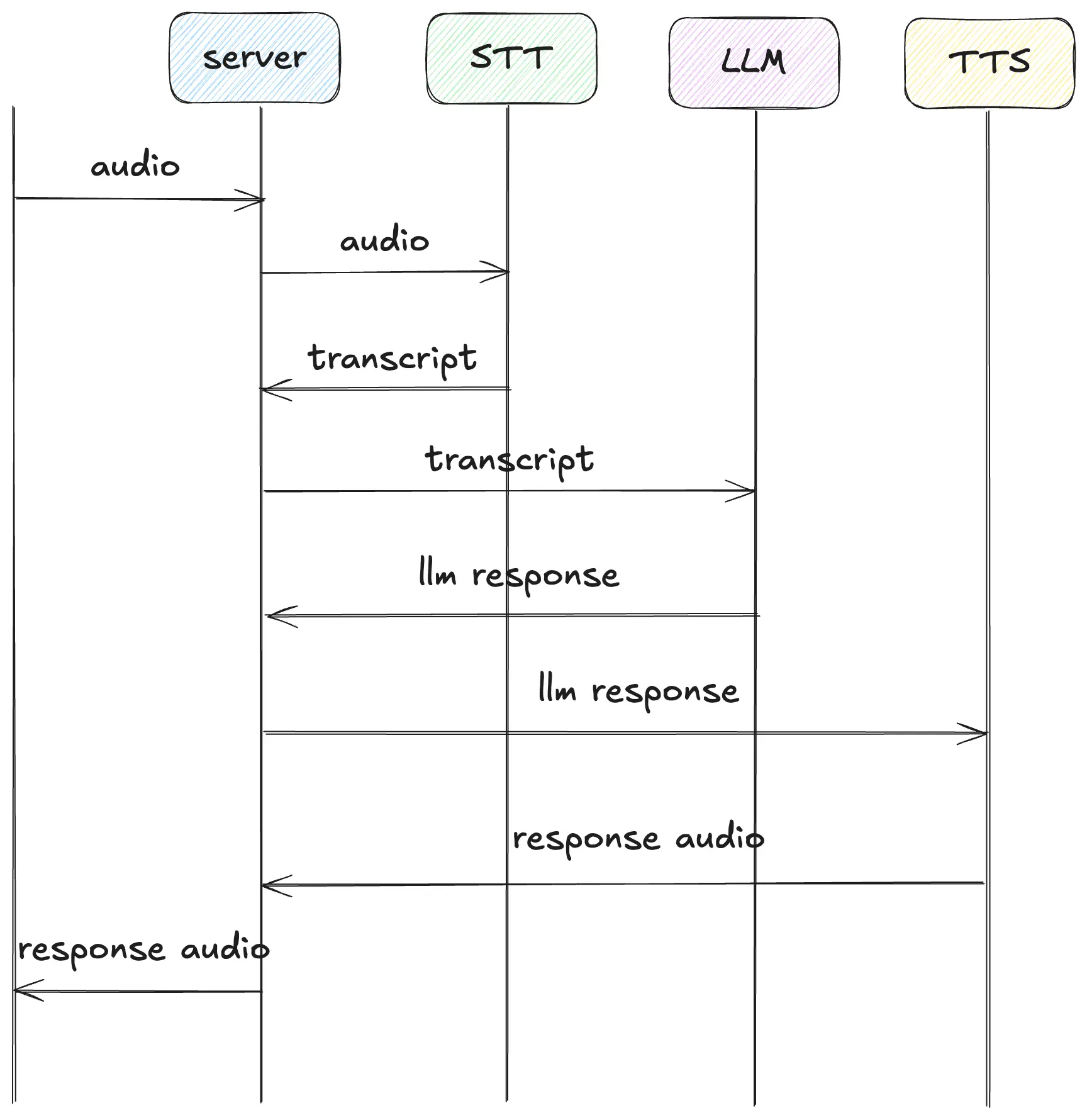
Our pipeline also needs a way to determine when the user finished speaking so we can start responding. This is where another crucial component of AI Voice Agents comes in: Voice Activity Detector (VAD).
A job of a VAD is to determine whether some chunk of audio contains speech. Once we know if chunk of audio contains speech, we can define a heuristic for responding. For example: we assume that 500ms of silence after a speech segment means that the user finished speaking and we can start working on a response.
Nowadays VAD is usually achieved using lightweight ML model so that would be a 4th model in our pipeline.

Voice Agent architecture
Real-World Challenges
This architecture wouldn’t work great in the real world because it assumes that the conversation is synchronous, i.e. the speaker starts speaking when the previous speaker finished speaking. Real-world conversations are messy: People interrupt, pause mid-sentence, or backchannel (“mhm,” “uh-huh”). To handle this, we needed to add a conversation orchestrator—a component to manage these complex interactions.
For example:
- Agent is speaking and the user interrupts. Should the Agent stop speaking, listen to the user's speech and respond to that speech? Or perhaps the user was just backchanneling and the Agent should continue talking?
- User is speaking and goes silent for a couple of hundred of milliseconds. This is enough for our VAD to detect the end of speech. We start working on a response and the user resumes the speech. Should we now respond to both speech fragments? Or only the last one?
While humans handle these situations effortlessly, programming them is much harder. Designing this orchestration involved countless “if” statements and tuning hyperparameters. But after this step we had a working Voice Agent!

Voice Agent architecture
def process(conversation: Conversation):
speech_result = check_for_speech(conversation)
if speech_result is None:
return ConversationState.HUMAN_SILENT
if speech_result.ended:
logger.info(
f"Human speach ended. Speach length: {speech_result.end_sample - speech_result.start_sample}. "
)
conversation.human_speech_ended(speech_result)
if conversation.agent_was_interrupted() and speech_result.is_short():
logger.info("🎙️🏁Short Human speech, agent was interrupted")
return ConversationState.SHORT_INTERRUPTION_DURING_AGENT_SPEAKING
if conversation.agent_was_interrupted() and speech_result.is_long():
logger.info("🎙️🏁Long Human speech, agent was interrupted")
return ConversationState.LONG_INTERRUPTION_DURING_AGENT_SPEAKING
if speech_result.is_short():
logger.info("🎙️🏁Short Human speech detected")
return ConversationState.SHORT_SPEECH
if speech_result.is_long():
logger.info("🎙️🏁Long Human speech detected")
return ConversationState.LONG_SPEECH
raise ValueError("🎙️🏁Human speech ended, but no state was matched")
elif not speech_result.ended:
if conversation.is_agent_speaking():
logger.info(
"🎙️🟢 Human and Agent are speaking."
)
return ConversationState.BOTH_SPEAKING
else:
logger.info("🎙️🟢 Human started speaking")
return ConversationState.HUMAN_STARTED_SPEAKINGOrchestator code
Testing
How do we tell if our Agent is actually any good? And how do we make sure the whole thing doesn’t break if we change one line in our fragile voice orchestrator? Our Voice Agent needs testing. We focused on two areas:
1. Agent quality: Does the Agent respond and perform actions as expected?
2. Conversation quality: Does the interaction flow naturally?
We will talk about testing conversation quality since many great pieces were written about LLM evaluations (you can check this great overview by Hamel Husain).
Manual Tests
To test conversation quality we started with manual tests. We have written a bunch of scenarios and checked whether the conversation had a good flow. And while it was helpful at the beginning it quickly became impractical:
- Tests were not repeatable (our speech intervals had some variance obviously).
- Finding the root cause of issues from logs after a conversation was a difficult task.
- Tests were taking a lot of time, we had to do hours of actual conversations with our Agent.
Overall manual testing led to a huge frustration so we looked into ways to perform automated testing.
Automated Tests
For automated tests we wanted them to be as close to the original conversation as possible. So we took our scenarios from manual tests and prerecorded parts of user speech. Then we simulated the conversation by streaming the audio chunks to our Agent. We would add assertions like:
- Agent should respond between time x and y
- Agent should stop talking between time x and y
"""
If human is talking and makes a long pause such that we detect that the speech ended, our agents starts thinking about response.
If human then resumes talking before agent started responding we should cancel the first response and listen until the second speech ends.
We should then respond to both segments at once.
The file contains an 8-second clip. Structure is the following
00.00 - 01.90 silence
01.90 - 03.00 speech (1st segment)
03.00 - 04.10 silence (pause)
04.10 - 05.10 speech (2nd segment)
05.10 - 07.85 silence
We expect the following:
- speech_to_text is called with about 1.1s of speech (1st segment)
- speech_to_text is called with about 3.2s of speech (1st and 2nd segments)
- response is sent to websocket only after the second speech is finished
"""One of the test cases we wrote
These tests were very fragile and hard to maintain, but they gave us some confidence that the conversation was working as intended.
Future of Automated Testing
At the time of our work on our own Voice Agents multiple startups (Coval, Hamming ai, Vocera) got accepted to YC with the promise of providing automated tests / simulations for Voice Agents (Coval has officially launched since then). While we didn’t have a chance to try them at the time, we love the idea behind those products. If these products will successfully do what they promise they will definitely play a key role in AI Voice Agents test stack in the future.
Sidenote: We are curious what approach do these companies take to test their own Agents.
Telephony
So far we have described how to create a Voice Agent, let’s now discuss how to add a telephony layer to it. If you have experience with telephony you can safely skip to the next section.
Prior to starting the project we haven’t worked with telephony. We learned quickly that there is basically a single company dominating the market - Twilio (btw. Its stock seems to be struggling now, is it a good time to buy?:)).
Twilio provides a bunch of APIs and products which allow developers to program phone conversations. One of its products is called Media Streams. The idea is that the user calls the number you have registered with Twilio and Twilio sets up a websocket to your server. This websocket will then be used to send audio chunks in both directions: user speech from Twilio to your server and Agent speech from your server to Twilio.
Apart from audio chunks, Twilio supports other types of messages which allow you to control the conversation, e.g. a clear message which clears the audio buffer on Twilios side and basically cancels your Agent speech. By integrating our conversation orchestrator with Twilio API we can achieve things like pausing when interrupted, replaying audio chunks and so on.
To make it easier and cheaper to test Voice Agents we’ve built a simple website that tries to simulate the Twilio Media Streams API, allowing us to test the conversation locally without using Twilio.

Website we used for testing the Voice Agent locally

Final architecture with telephony layer
Reality Check
We had a working platform that could in theory be used with arbitrary AI Agent to serve different domains. We learned a lot and the final result was really cool, but we needed to finally answer one question: does it make sense to maintain all of this code just to build a Phone Agent? Couldn’t we simply use one of the existing providers?
We came to the conclusion that building your own conversational platform makes sense if :
- You’re selling the platform itself
- You are big enough that is actually cheaper to build and use your own platform
- You have custom requirements not covered by existing platforms
We didn’t fall into any of these 3 categories. Also, we felt that our main strength was building good and thoroughly evaluated AI Agents, not the conversational platform. The space of the Phone Agent platforms is really packed plus there is always the risk that OpenAI will come and basically eat the whole industry. Thus we decided to return the original idea of using an external provider.
Phone Agent Platforms
Before we go into evaluating specific products, let’s think about what are the desired properties of a Phone Agent platform. For us it were the following:
- Conversation flow - does the conversation feel natural
- Latency - are the Agents response time consistently low? We aimed for less than 2 seconds for Agent response
- Agent quality - does the Agent follow the script (prompt)?
- Availability
- Speech transcription / speech generation correctness - does the Agent support Polish language well?
We have tested 3 platforms: bland.ai, vapi.ai and retellai.com.
Vapi and Retell are quite similar to what we have built - they provide conversation orchestration and make all the blocks (STT, TTS, LLM) pluggable. For example on Vapi you could use deepgram as a transcriber, ElevenLabs for text to speech and OpenAI for LLM. Both Vapi and Retell allow you to specify your own endpoint for text generation which enables you to use basically every model for the LLM part. These two platforms take care of the hard parts of conversation flow and let developers focus on Agent quality.
Bland takes a very different approach. They host all the models themselves and provide a conversation abstraction called Pathways. The idea is that you describe the conversation as a flow chart, at each stage describing what the Agent is supposed to do (with natural language).
These are 2 very different philosophies each with its pros and cons.
The Bland self-hosted approach has serious benefits:
- latency - because they host all of their models in the same location it's the best in class. With Bland the response latency was consistently around 1.5s whereas for other providers it was no less than 2.5s.
- availability - since Bland does not rely on external providers (except probably Twilio and AWS) it is much less prone to outages then other platforms which use multiple providers underneath.
But it also had drawbacks:
- Since you can’t point Bland to your own Agent for the LLM part, you must write all the Agent logic and prompts in Bland UI. This was a deal breaker for us, because it meant we couldn’t reliably evaluate the Agent. Bland provides some in browser testing capabilities but this was very far from what we are used to when evaluating the Agents. (As a side note this made us wonder who this product is actually for? For us, it seemed there was not enough control for production workflows to be used by developers, and it seemed too complex to be used by non-technical folks)
- The transcription model quality was poor for Polish language
Bland's weaknesses are Vapi's and Retell's strengths and vice versa:
- Since we could provide an endpoint for the LLM we can have all the Agent logic on our backend server. This meant that we could write and evaluate a regular Agent which gave us a lot of control and confidence that the Agent works.
- Latency was 2.5s at best and there were spikes up to 7s! This is because each speech segment has to go through multiple providers before the response. These providers have variable response time latency and the total variance at the end is really high.
- Availability - with each added provider the expected availability is lowered. If you have 3 different providers each with 99% SLA then the expected SLA is just 97%.
- Speech transcription - there is a notable difference between Retell and Vapi here. Retell handles transcription on its side and it was really poor for Polish. With Vapi on the other hand we were able to find a provider which had good quality for our mother tongue.
The table below summarises our findings:

The winner? We wanted to go with Bland because it was so snappy. But with lack of control over the Agent logic and poor transcription quality we couldn't make it work. We ended up using Vapi.
Future of Phone Agents
Lastly, we would like to share how we envision the future of AI Agents space:
- STT and TTS: Abstracted away for developers.
- Seamless conversations: No need for extensive hyperparameter tuning.
- Self-hosted models: Improved latency and availability.
- Pluggable LLMs: Developers retain full control over conversation logic and are able to perform evaluations.
- Lower costs: cost per minute much lower than that of humans.
- Simulation-based evaluations: Automated testing frameworks will become standard, with open-source alternatives emerging.
This is an exciting space, and we can’t wait to see how it evolves.
If you are interested in the code, let us know by tagging @bnowako or @moscicky on X, we can open source it.
Thanks for reading!
| Btw. we just released Job Board for AI Agents. Check it out